йҡҸзқҖзӨҫдәӨеӘ’дҪ“зҡ„е…ҙиө·пјҢи·ЁиЎҢдёҡзҡ„дјҒдёҡи¶ҠжқҘи¶Ҡдҫқиө–зӨҫдәӨеӘ’дҪ“её–еӯҗзҡ„жғ…ж„ҹеҲҶжһҗпјҢд»ҘжӣҙеҘҪең°дәҶ解他们зҡ„е®ўжҲ·жҲ–е…¬дј—еҜ№е…¶дә§е“ҒгҖҒжңҚеҠЎгҖҒе“ҒзүҢеҪўиұЎжҲ–иҗҘй”Җжҙ»еҠЁгҖҒд»ҘеҸҠ他们зҡ„з«һдәүеҜ№жүӢзҡ„ж„Ҹи§ҒгҖӮеҮҶзЎ®е…Ёйқўзҡ„дәҶи§Је…¬дј—ж„Ҹи§ҒжңүеҠ©дәҺжҺЁеҠЁиҗҘй”ҖгҖҒй”Җе”®гҖҒдә§е“Ғи®ҫи®ЎгҖҒжңҚеҠЎиҙЁйҮҸгҖҒйЎҫе®ўеҝ иҜҡеәҰзӯүж–№йқўгҖӮ еҸҠж—¶еҸ‘зҺ°йҮҚеӨ§зҡ„иҙҹйқўдәӢ件д№ҹжңүеҠ©дәҺжңүж•Ҳзҡ„еҚұжңәз®ЎзҗҶпјҢдјҒдёҡеҸҜд»Ҙиҝ…йҖҹдҪңеҮәеҸҚеә”пјҢе°ҪйҮҸеҮҸе°‘д»»дҪ•дёҚеҸҜйў„и§Ғзҡ„иҙҹйқўж¶ҲжҒҜзҡ„еҪұе“ҚгҖӮ
жғ…ж„ҹеҲҶжһҗжҳҜдёҖдёӘеӨҚжқӮдё”е…·жңүжҢ‘жҲҳжҖ§зҡ„д»»еҠЎ
дёҖиҲ¬жқҘиҜҙпјҢеңЁж–Үжң¬еҲҶжһҗдёӯпјҢжғ…ж„ҹеҲҶжһҗж—ЁеңЁзЎ®е®ҡж–Үз« зҡ„жӯЈйқўгҖҒиҙҹйқўжҲ–дёӯжҖ§зҡ„ж„Ҹи§ҒжһҒжҖ§гҖӮиҝҷеҗ¬иө·жқҘеҫҲзӣҙжҺҘпјҢдҪҶдәӢе®һдёҠпјҢиҝҷжҳҜдёҖдёӘеӨҚжқӮдё”е…·жңүжҢ‘жҲҳжҖ§зҡ„д»»еҠЎгҖӮ
жғ…з»ӘжҳҜдёҖдёӘйқһеёёдё»и§Ӯзҡ„дәӢжғ…гҖӮдёҚеҗҢзҡ„иҜ»иҖ…еңЁйҳ…иҜ»еҗҢдёҖзҜҮж–Үз« ж—¶еҸҜиғҪдјҡжңүдёҚеҗҢзҡ„еҸҚеә”гҖӮд»ҘеҫҖзҡ„з ”з©¶иЎЁжҳҺпјҢдёҚеҗҢдәәеҜ№ж–Үжң¬жғ…ж„ҹзҡ„е…ёеһӢи®ӨеҗҢдҪҺдәҺ 85пј…гҖӮж №жҚ®жҲ‘们иҮӘе·ұзҡ„з»ҸйӘҢпјҢиҝҷдёӘж•°еӯ—еҜ№дәҺжӣҙеӨҚжқӮзҡ„иҜқйўҳз”ҡиҮіжӣҙдҪҺгҖӮдҫӢеҰӮпјҢеңЁжҲ‘们зҡ„дёҖдёӘйЎ№зӣ®дёӯпјҢеҲҶжһҗзӨҫдәӨеӘ’дҪ“зҡ„з”ЁжҲ·еҜ№иӮЎзҘЁдәӨжҳ“зҡ„зңӢжі•пјҢеҸӮдёҺиҖ…д№Ӣй—ҙиҫҫжҲҗе…ұиҜҶзҡ„д»…д»…еҚ дёҚеҲ° 65пј…гҖӮз”ұдәҺд»»дҪ•иҮӘеҠЁеҢ–жғ…ж„ҹеҲҶжһҗеј•ж“Һзҡ„еҮҶзЎ®жҖ§йғҪжҳҜзӣёеҜ№дәҺдәәдёәеҲӨж–ӯпјҲжүҖи°“зҡ„й»„йҮ‘ж ҮеҮҶпјүиҝӣиЎҢиЎЎйҮҸзҡ„пјҢеӣ жӯӨйҮҚиҰҒзҡ„жҳҜиҰҒж №жҚ®еӨҡдёӘжіЁйҮҠиҖ…зӣёдә’еҗҢж„Ҹзҡ„ж ҮжіЁж•°жҚ®иҝӣиЎҢиЎЎйҮҸпјҢиҖҢдёҚжҳҜд»…дҫқиө–е”ҜдёҖзҡ„жіЁйҮҠиҖ…пјӣеҗҢж ·йҮҚиҰҒзҡ„жҳҜпјҡ85пј…пјҲеҚідәәзұ»жғ…ж„ҹе…ұиҜҶж°ҙе№іпјүйҖҡеёёиў«и®ӨдёәжҳҜд»»дҪ•иҮӘеҠЁеҢ–жғ…з»ӘеҲҶжһҗеј•ж“Һзҡ„еҮҶзЎ®жҖ§зҡ„зҗҶи®әдёҠйҷҗгҖӮй’ҲеҜ№дёҖдёӘе°ҸеһӢе°Ғй—ӯзҡ„жөӢиҜ•ж•°жҚ®йӣҶпјҢжҲ–иҖ…еҹәдәҺдёҖдёӘдәәзҡ„еҲӨж–ӯпјҢеј•ж“ҺеҸҜд»ҘиҫҫеҲ°й«ҳдәҺ 85пј… з”ҡиҮі 90пј… зҡ„жғ…ж„ҹеҲҶжһҗеҮҶзЎ®еәҰгҖӮ然иҖҢпјҢеңЁй’ҲеҜ№ејҖж”ҫйўҶеҹҹж•°жҚ®зҡ„ж—¶еҖҷпјҢд»»дҪ•и¶…иҝҮ 90пј… еҲҶжһҗеҮҶзЎ®зҺҮзҡ„иҜҙжі•йғҪжӣҙеғҸжҳҜе№»жғіпјҢиҖҢдёҚе…·жңүзҺ°е®һжҖ§гҖӮ
дәә们常常и®ӨдёәзӨҫдәӨеӘ’дҪ“е’Ңж–°й—»ж–Үз« зҡ„жғ…ж„ҹеҲҶжһҗжҳҜдёҖж ·зҡ„пјҢеӣ дёәе®ғ们йғҪеӨ„зҗҶж–Үжң¬гҖӮдәӢе®һдёҠпјҢ他们д№Ӣй—ҙз®ҖзӣҙжҳҜеӨ©еЈӨд№ӢеҲ«гҖӮзӨҫдәӨеӘ’дҪ“её–еӯҗжҲ–з”ЁжҲ·иҜ„и®әж–Үз« зҡ„дҪңиҖ…еҸҜд»ҘеңЁж–Үжң¬дёӯжҳҺзЎ®ең°иЎЁиҫҫ他们зҡ„ж„Ҹи§ҒпјҲеҰӮпјҡдёҚе–ңж¬ўпјҢжҲ–еҘҪдёҺеқҸпјүпјӣиҖҢж–°й—»жҠҘйҒ“зҡ„дҪңиҖ…еҲҷдёҚеӨӘеҸҜиғҪеңЁжЎҲж–ҮдёӯйңІйӘЁең°ејәеҠ 他们зҡ„дёӘдәәж„Ҹи§Ғ/еҲӨж–ӯгҖӮзӣёеҸҚпјҢж–°й—»дәӢ件жң¬иә«еҸҜиғҪдјҡеҜјиҮҙиҜ»иҖ…еҜ№з§ҜжһҒзҡ„пјҢж¶ҲжһҒзҡ„жҲ–дёӯз«Ӣзҡ„ж„ҹи§үеҒҡеҮәдёҚеҗҢзҡ„еҸҚеә”гҖӮеҗҢж ·зҡ„ж–°й—»ж–Үз« еҫҖеҫҖдјҡеҜјиҮҙдёҚеҗҢзҡ„и§ӮзӮ№пјҢиҝҷеҸ–еҶідәҺиҜ»иҖ…жҳҜи°ҒгҖӮдҫӢеҰӮпјҢе…ідәҺ A е…¬еҸёиөўеҫ—дәҶй’ҲеҜ№ B е…¬еҸёиҜүи®јзҡ„ж–Үз« пјҢA е…¬еҸёе’Ң B е…¬еҸёзҡ„дәәдјҡжңүе®Ңе…ЁзӣёеҸҚзҡ„жғ…з»ӘгҖӮеӣ жӯӨпјҢйңҖиҰҒз”ЁдёҚеҗҢзҡ„жҠҖжңҜжқҘеӨ„зҗҶй’ҲеҜ№зӨҫдәӨеӘ’дҪ“жҲ–й’ҲеҜ№ж–°й—»зҡ„жғ…ж„ҹеҲҶжһҗгҖӮ
иҜӯиЁҖеҫҲеӨҚжқӮгҖӮи®ҪеҲәгҖҒжӯ§д№үгҖҒеӨҡд№үжҖ§гҖҒеҗҰе®ҡжҖ§е’ҢдҝҡиҜӯйғҪжҳҜжңәеҷЁйҡҫд»ҘзҗҶи§Јзҡ„еӣ зҙ пјҢеҜ№жғ…ж„ҹеҲҶжһҗжңүе·ЁеӨ§зҡ„еҪұе“ҚгҖӮеӣ жӯӨпјҢз®ҖеҚ•зҡ„еҹәдәҺеӯ—е…ёзҡ„ж–№жі•еҫҖеҫҖж— жі•еҲҶжһҗеӨҚжқӮзҡ„жғ…ж„ҹиЎЁиҫҫгҖӮ
дәә们йҖҡеёёе–ңж¬ўжҜ”иҫғдёҚеҗҢзҡ„дё»дҪ“пјҢдҫӢеҰӮдә§е“ҒгҖҒеҠҹиғҪжҲ–е“ҒзүҢпјҢиҝҷеңЁд»–们зҡ„зӨҫдәӨеӘ’дҪ“её–еӯҗдёӯеҸҜи§ҒдёҖж–‘гҖӮж–°й—»жҠҘйҒ“д№ҹеҸҜиғҪеңЁдёҖдёӘеҚ•дёҖзҡ„жҠҘе‘ҠдёӯжҸҗеҸҠеӨҡдёӘе®һдҪ“пјҢдҫӢеҰӮе…¬еҸёжҲ–дёӘдәәгҖӮе…Ёж–ҮжЎЈзә§еҲ«зҡ„иҮӘеҠЁеҢ–жғ…ж„ҹеҲҶжһҗзӣёеҜ№е®№жҳ“е®һзҺ°пјҢдҪҶеҫҲйҡҫе®һзҺ°еңЁж–Үжң¬дёӯиҜҶеҲ«ж„Ҹи§ҒдёҺж„Ҹи§ҒжҢҒжңүиҖ…д№Ӣй—ҙзҡ„жӯЈзЎ®е…іиҒ”гҖӮеёӮеңәдёҠзҡ„еӨ§еӨҡж•°дҫӣеә”е•ҶеҸӘжҳҜеӣһеә”ж–ҮжЎЈзә§зҡ„жғ…з»ӘеҲҶжһҗпјҢд»ҘиҺ·еҫ—еҚ•дёҖзҡ„ж„Ҹи§ҒжһҒжҖ§пјӣ然еҗҺе°Ҷе…¶дёҺжң¬ж–ҮжҸҗеҲ°зҡ„е®һдҪ“пјҲе…¬еҸёпјҢдә§е“ҒжҲ–е“ҒзүҢзӯүпјүиҝӣиЎҢз®ҖеҚ•зӣҙжҺҘзҡ„е…іиҒ”пјҲйҖҡеёёйҖҡиҝҮеҹәдәҺ规еҲҷзҡ„е…ій”®еӯ—еҢ№й…ҚжқҘжЈҖжөӢпјүгҖӮжҲ‘们йңҖиҰҒжӣҙе…Ҳиҝӣзҡ„жҠҖжңҜжқҘе®һзҺ°жӣҙеҮҶзЎ®зҡ„дё»дҪ“жҲ–е®һдҪ“зә§еҲ«зҡ„жғ…ж„ҹеҲҶжһҗгҖӮ
жғ…ж„ҹеҲҶжһҗжҠҖжңҜ/ж–№жі•
еңЁејәи°ғдәҶжүҖжңүе…ідәҺжғ…ж„ҹеҲҶжһҗзҡ„жҢ‘жҲҳжҲ–иҜҜи§Јд№ӢеҗҺпјҢи®©жҲ‘们жқҘи°Ҳи°ҲиҮӘеҠЁжғ…з»ӘеҲҶжһҗжңүе“ӘдәӣжҠҖжңҜ/ж–№жі•еҸҜз”ЁгҖӮ
еҹәдәҺиҜҚе…ёзҡ„ж–№жі•пјҡ
е®ғдҫқйқ еҹәдәҺйў„е®ҡд№үзҡ„еӯ—е…ёд»Һж–Үжң¬дёӯжҸҗеҸ–жғ…ж„ҹе…ій”®еӯ—жҲ–е…ій”®зҹӯиҜӯпјӣ然еҗҺж №жҚ®дёҖдәӣзЎ¬зј–з Ғзҡ„иҜ„еҲҶе…¬ејҸпјҲдҫӢеҰӮеӨҡж•°зҘЁжҲ–еҠ жқғжҖ»з»“пјүжҺЁеҜјеҮәжғ…з»ӘеҲӨж–ӯгҖӮеӨ§еӨҡж•°е…¬ејҖеҸҜз”Ёзҡ„жғ…ж„ҹиҜҚе…ёйҖҡеёёз”ұеӯҰжңҜз ”з©¶дәәе‘ҳеҲ¶дҪңгҖӮеҰӮжһңжІЎжңүи¶іеӨҹзҡ„иө„йҮ‘е’ҢдәәеҠӣпјҢиҝҷдәӣеӯ—е…ёеҫҖеҫҖиў«еҫҲеҝ«ең°з”ҹдә§еҮәжқҘиҖҢдё”зјәд№ҸиҙЁйҮҸжҺ§еҲ¶гҖӮйҖҡеёёжқҘиҜҙпјҢжғ…ж„ҹиҜҚе…ёеҜ№дәҺиӢұиҜӯжҜ”еҜ№е…¶д»–иҜӯиЁҖжӣҙе®№жҳ“е®ҡд№үпјҢеӣ дёәиӢұиҜӯжҳҜиҝ„д»ҠдёәжӯўеңЁиҮӘ然иҜӯиЁҖеӨ„зҗҶпјҲNLPпјүдёӯз ”з©¶жңҖеӨҡзҡ„иҜӯиЁҖгҖӮеҫҲеӨҡж—¶еҖҷпјҢдәә们еҸӘжҳҜзҝ»иҜ‘иӢұж–Үжғ…ж„ҹиҜҚе…ёпјҢ并用е®ғжқҘеҲҶжһҗе…¶д»–иҜӯиЁҖзҡ„ж–Үжң¬гҖӮ然иҖҢпјҢзҝ»иҜ‘зҡ„е…ій”®еӯ—е’ҢзҹӯиҜӯеҸҜиғҪдёҚе®Ңе…ЁйҖӮз”ЁдәҺе…¶д»–иҜӯиЁҖпјҢзү№еҲ«жҳҜйқһжӢүдёҒиҜӯиЁҖгҖӮзЎ¬зј–з Ғзҡ„жғ…з»Әе…¬ејҸжҳҜеғөеҢ–зҡ„пјҢжүҖд»ҘеҸҜиғҪж— жі•ж¶өзӣ–жүҖжңүжғ…еҶөпјӣ并且пјҢиҝҷдәӣе…¬ејҸиҝҳдҫқиө–дәҺе®ҡд№үе®ғ们зҡ„дәәзҡ„зҹҘиҜҶгҖӮ
еҹәдәҺжңәеҷЁеӯҰд№ зҡ„ж–№жі•пјҡ
е®ғдҫқиө–дәҺд»Һи®ӯз»ғж•°жҚ®йӣҶдёӯеӯҰд№ жҹҗз§Қ вҖңд»Ҙж•°еӯҰ/з»ҹи®ЎеӯҰе®ҡд№үзҡ„еҲҶзұ»жЁЎеһӢвҖқ зҡ„еҶізӯ–еҸӮж•°пјҢжӯӨи®ӯз»ғж•°жҚ®йӣҶз”ұеӨ§йҮҸзҡ„пјҢз”ұдәәзұ»жүӢеҠЁж Үи®°зҡ„е…ідәҺ他们зҡ„жғ…ж„ҹжһҒжҖ§зҡ„ж–Үз« з»„жҲҗгҖӮи®ёеӨҡеӣ зҙ йғҪеҸҜиғҪеҶіе®ҡжңәеҷЁеӯҰд№ еһӢжғ…ж„ҹеҲҶзұ»еҷЁзҡ„жңүж•ҲжҖ§гҖӮ
жңәеҷЁеӯҰд№ зҡ„жЁЎеһӢпјҡдёҚеҗҢзҡ„жңәеҷЁеӯҰд№ жЁЎеһӢиў«и®ҫи®Ўдёәе…·жңүдёҚеҗҢзҡ„еҹәзЎҖж•°еӯҰжҲ–з»ҹи®ЎеҒҮи®ҫгҖӮдәә们жҲ–и®ёи®ӨдёәдёҖдёӘжӣҙеӨҚжқӮзҡ„жЁЎеһӢе°Ҷи¶…и¶ҠдёҖдёӘжӣҙз®ҖеҚ•зҡ„жЁЎеһӢпјҢдҪҶдәӢе®һ并йқһжҖ»жҳҜеҰӮжӯӨгҖӮеӣ жӯӨпјҢеңЁйҖүжӢ©жҹҗз§ҚжЁЎеһӢд№ӢеүҚпјҢдәҶи§ЈдҪ еҠӣеӣҫеә”з”Ёиҝҷз§ҚжЁЎеһӢдәҺе…¶дёҠзҡ„ж•°жҚ®жҳҜеҗҰз¬ҰеҗҲжЁЎеһӢзҡ„еҹәжң¬еҒҮи®ҫжҳҜйқһеёёйҮҚиҰҒзҡ„гҖӮи®ёеӨҡжІЎжңүз»ҸиҝҮйҖӮеҪ“еҹ№и®ӯзҡ„жүҖи°“зҡ„ вҖңж•°жҚ®з§‘еӯҰ家вҖқ еҫҖеҫҖзјәд№Ҹиҝҷж–№йқўзҡ„зҹҘиҜҶгҖӮ
зү№еҫҒпјҢеҚіеҺҹе§Ӣж–Үжң¬еҰӮдҪ•д»Ҙж•°еӯҰеҪўејҸиЎЁзӨәгҖӮеҺҹе§Ӣеӯ—з¬ҰжҲ–еҚ•иҜҚдёҚиғҪзӣҙжҺҘйҰҲйҖҒеҲ°жңәеҷЁеӯҰд№ жЁЎеһӢдёӯгҖӮ他们еҝ…йЎ»д»Ҙжҹҗз§Қж–№ејҸиҪ¬жҚўжҲҗж•°еӯҰеҪўејҸзҡ„еҖјгҖӮжҲ‘们称иҝҷдёӘиҝҮзЁӢдёәзү№еҫҒжҸҗеҸ–жҲ–зү№еҫҒе·ҘзЁӢгҖӮи®ҫи®ЎдјҳиүҜзҡ„зү№еҫҒе°ҶжҜ”и®ҫи®ЎдёҚдҪізҡ„зү№еҫҒиЎЁзҺ°жӣҙеҘҪгҖӮдҫӢеҰӮпјҢNLP дёӯжңүдёҖз§ҚжөҒиЎҢдё”з®ҖеҚ•зҡ„зү№еҫҒиў«з§°дёә bag-of-wordsпјҢеҚіеҸҘеӯҗ/ж–Үз« дёӯзҡ„жҜҸдёӘеҚ•иҜҚз”ұ 0 жҲ– 1 иЎЁзӨәпјҢе…¶дёӯ 1 иЎЁзӨәе…¶еңЁж–Үжң¬дёӯзҡ„еӯҳеңЁпјҢеҗҰеҲҷдёә 0гҖӮе®ғеңЁдёҖдёӘеҘҪзҡ„и®ӯз»ғж•°жҚ®йӣҶдёҠйҖҡеёёеҸҜд»Ҙе·ҘдҪңеҫ—дёҚй”ҷгҖӮ然иҖҢпјҢе®ғеҫҖеҫҖдёҚиғҪеӨ„зҗҶжӣҙеӨҚжқӮзҡ„иҜӯиЁҖиЎЁиҫҫпјҢжҜ”еҰӮеүҚж–ҮжҸҗеҲ°зҡ„и®ҪеҲәпјҢеҗ«зіҠпјҢеӨҡд№үе’ҢеҗҰе®ҡпјҢеӣ дёәе®ғеңЁи®ҫи®ЎдёҠе°ұдёҚжҳҜз”ЁжқҘзј–з ҒиҝҷдәӣдҝЎжҒҜзҡ„гҖӮ
и®ӯз»ғж•°жҚ®пјҡеҜ№дәҺжңәеҷЁеӯҰд№ зі»з»ҹжқҘиҜҙпјҢжҸҗдҫӣй«ҳиҙЁйҮҸзҡ„и®ӯз»ғж•°жҚ®йӣҶжҳҜйқһеёёйҮҚиҰҒзҡ„гҖӮжүҖи°“й«ҳиҙЁйҮҸе°ұжҳҜиҜҙпјҡиҜҘи®ӯз»ғж•°жҚ®йӣҶеҜ№дәҺеӯҰд№ д»»еҠЎжқҘиҜҙи¶іеӨҹеӨ§пјҢиҖҢеҜ№дәҺзӣ®ж Үеә”з”ЁиҖҢиЁҖжӣҙеӨ§зҡ„дёҚеҸҜи§Ғзҡ„ж•°жҚ®е…·жңүи¶іеӨҹзҡ„д»ЈиЎЁжҖ§гҖӮеҰӮжһңи®ӯз»ғж•°жҚ®зҡ„д»ЈиЎЁжҖ§дёҚжҳҜеҫҲеҘҪпјҢйӮЈд№Ҳе°Ҫз®ЎеңЁи®ӯз»ғйӣҶдёҠеҸҜд»ҘиҺ·еҫ—йқһеёёй«ҳзҡ„еҮҶзЎ®еәҰпјҢе®ғеңЁе®һйҷ…еә”з”ЁдёӯпјҲin the wildпјүд№ҹдјҡиЎЁзҺ°дёҚдҪіпјҢиҝҷе°ұжҳҜжңәеҷЁеӯҰд№ йўҶеҹҹдёӯзқҖеҗҚзҡ„ вҖңиҝҮеәҰжӢҹеҗҲвҖқ й—®йўҳгҖӮ
еҹәдәҺж·ұеәҰеӯҰд№ зҡ„ж–№жі•пјҡ
ж·ұеәҰеӯҰд№ жҳҜжңәеҷЁеӯҰд№ з®—жі•зҡ„дёҖдёӘеӯҗйӣҶпјҢеӣ дёәжҳҜеҸ—еҲ°дәәи„‘иҝһжҺҘе’ҢеӯҰд№ жңәеҲ¶зҡ„еҗҜеҸ‘пјҢжүҖд»Ҙд№ҹиў«з§°дёәж·ұеәҰзҘһз»ҸзҪ‘з»ңгҖӮиҮӘ 20 дё–зәӘ 40 е№ҙд»Јд»ҘжқҘпјҢдәәе·ҘзҘһз»ҸзҪ‘з»ңзҡ„з ”з©¶дёҖзӣҙеңЁиҝӣиЎҢпјҢиҝҮеҺ»жӣҫжңүи®ёеӨҡиө·иө·иҗҪиҗҪгҖӮж·ұеәҰзҘһз»ҸзҪ‘з»ңжҲ–ж·ұеәҰеӯҰд№ зҡ„жңҖж–°жөӘжҪ®еҫ—зӣҠдәҺи®Ўз®—жүҖйңҖзҡ„硬件пјҢиҪҜ件е’ҢеӯҰд№ зҗҶи®әзҡ„жңҖж–°иҝӣеұ•гҖӮдё»иҰҒзҡ„жҰӮеҝөжҳҜпјҢз»ҷе®ҡе……еҲҶзҡ„и®ӯз»ғж•°жҚ®пјҢдёҖдёӘе…·жңүи¶іеӨҹеӨҡеұӮж¬Ўе’ҢзҘһз»Ҹе…ғзҡ„ж·ұеәҰзҘһз»ҸзҪ‘з»ңе°ҶиғҪеӨҹд»ҺеҺҹе§Ӣж•°жҚ®дёӯеӯҰд№ еҮәиүҜеҘҪзҡ„иЎЁзӨәпјҲиҜ‘иҖ…жіЁпјҡд№ҹеҸҜиҜ‘дёәиЎЁеҫҒпјүпјҢд»ҺиҖҢеҸҜд»Ҙж¶ҲйҷӨеңЁе…ёеһӢжңәеҷЁеӯҰд№ иҢғдҫӢдёӯеӣ°йҡҫе’ҢиҖ—ж—¶зҡ„зү№еҫҒе·ҘзЁӢжӯҘйӘӨпјӣиҝҷдәӣиҮӘеҠЁеӯҰд№ еҮәзҡ„иЎЁзӨәеҸҜд»Ҙеј•еҮәжӣҙеҘҪзҡ„й—®йўҳжұӮи§ЈпјҲйў„жөӢжҲ–еҲҶзұ»пјүгҖӮиҝ‘е№ҙжқҘпјҢж·ұеәҰеӯҰд№ еңЁеӣҫеғҸиҜҶеҲ«пјҢиҜӯйҹіиҜҶеҲ«пјҢNLP ж–№йқўеҸ–еҫ—дәҶйҮҚеӨ§зӘҒз ҙгҖӮ然иҖҢпјҢж·ұеәҰеӯҰд№ йҖҡеёёйңҖиҰҒжҜ”жңәеҷЁеӯҰд№ еӨҡеҫ—еӨҡзҡ„и®ӯз»ғж•°жҚ®пјҢеӣ дёәе®ғзҡ„жЁЎеһӢеӨҚжқӮжҖ§е’Ңи°ғи°җжүҖйңҖзҡ„еҸӮж•°ж•°йҮҸгҖӮеҜ№дәҺйӮЈдәӣйҡҫд»ҘиҺ·еҫ—и®ӯз»ғж•°жҚ®пјҢжҲ–и®ӯз»ғж•°жҚ®зЁҖе°‘зҡ„зӣ®ж Үеә”з”ЁпјҢз ”з©¶иЎЁжҳҺпјҢж·ұеәҰеӯҰд№ дёҚдёҖе®ҡдјҡиғңиҝҮдј з»ҹзҡ„жңәеҷЁеӯҰд№ пјӣиҖҢдё”ж·ұеәҰеӯҰд№ жҜ”жңәеҷЁеӯҰд№ жӣҙе®№жҳ“иҝҮеәҰжӢҹеҗҲгҖӮеңЁдёҖдёӘе°ҸеһӢеҸ—жҺ§ж•°жҚ®йӣҶдёӯпјҲи®ёеӨҡеӯҰжңҜеҹәеҮҶж•°жҚ®йӣҶе°ұжҳҜиҝҷз§Қжғ…еҶөпјүпјҢж·ұеәҰеӯҰд№ йҖҡеёёиҫҫеҲ°жңҖеҘҪзҡ„зІҫеәҰпјҢдҪҶе®ғеңЁе®һйҷ…ејҖж”ҫйўҶеҹҹж•°жҚ®дёӯзҡ„еә”з”ЁеҲҷеҸ–еҶідәҺи®ӯз»ғж•°жҚ®зҡ„д»ЈиЎЁжҖ§гҖӮе°ұжғ…ж„ҹеҲҶжһҗиҖҢиЁҖпјҢжҲ‘们зҡ„з ”з©¶з»“жһңиЎЁжҳҺпјҢзҺ°жҲҗзҡ„йқһе®ҡеҲ¶еҢ–ж·ұеәҰеӯҰд№ жЁЎеһӢеҫҖеҫҖжӣҙеҖҫеҗ‘дәҺеӯҰд№ ж–Үз« зҡ„иғҢжҷҜиҜқйўҳдҝЎжҒҜпјҢиҖҢдёҚжҳҜж–Үз« дёӯзҡ„зү№е®ҡжғ…ж„ҹдҝЎжҒҜпјӣжүҖд»Ҙе®ғ们еҜ№иҜқйўҳеҲҶзұ»зҡ„иЎЁзҺ°дјҡйқһеёёдёҚй”ҷпјҢдҪҶжҳҜе®ғ们й’ҲеҜ№жғ…ж„ҹеҲҶжһҗзҡ„еҮҶзЎ®жҖ§еңЁејҖж”ҫзҡ„ж•°жҚ®жөӢиҜ•дёӯз»ҸеёёдјҡеӨ§еӨ§йҷҚдҪҺгҖӮе°Ҫз®ЎеҰӮжӯӨпјҢж·ұеәҰеӯҰд№ еңЁи§ЈеҶіж–Үжң¬жғ…ж„ҹеҲҶжһҗй—®йўҳж–№йқўд»Қ然具жңүе·ЁеӨ§зҡ„жҪңеҠӣгҖӮз§ҜзҙҜжӣҙеӨҡзҡ„и®ӯз»ғж•°жҚ®пјҢйҮҮз”ЁеҚҠзӣ‘зқЈеӯҰд№ пјҢ并е°Ҷе…¶дёҺиҜӯиЁҖеӯҰзҹҘиҜҶзӣёз»“еҗҲпјҢжҳҜејҖеҸ‘жӣҙеҘҪзҡ„еҹәдәҺж·ұеәҰеӯҰд№ зҡ„жғ…ж„ҹеҲҶжһҗжЁЎеһӢзҡ„ж–№еҗ‘гҖӮ
з»јдёҠжүҖиҝ°пјҢж–Үжң¬жғ…ж„ҹеҲҶжһҗжҳҜеҸ—иҜ»иҖ…дё»и§ӮжҖ§е’ҢиҜӯиЁҖеӨҚжқӮжҖ§еҪұе“Қзҡ„пјҢе…·жңүжҢ‘жҲҳжҖ§зҡ„д»»еҠЎгҖӮ жңүдёҖдәӣзҺ°жңүзҡ„жҠҖжңҜеҸҜд»Ҙи§ЈеҶіиҮӘеҠЁеҢ–зҡ„жғ…ж„ҹеҲҶжһҗй—®йўҳпјҢеҢ…жӢ¬иҜҚе…ёпјҢжңәеҷЁеӯҰд№ е’ҢеҹәдәҺж·ұеәҰеӯҰд№ зҡ„ж–№жі•гҖӮ 然иҖҢпјҢеҜ№дәҺејҖж”ҫйўҶеҹҹзҡ„ж•°жҚ®жғ…ж„ҹеҲҶжһҗпјҢд»Қ然жңүдёҖдәӣйҷҗеҲ¶е’Ңж”№иҝӣз©әй—ҙгҖӮ
жҖқиҖғй—®йўҳ
йҖүжӢ©жғ…ж„ҹеҲҶжһҗзҡ„и§ЈеҶіж–№жЎҲж—¶пјҢдёҚиҰҒеҝҳи®°жҸҗеҮәд»ҘдёӢй—®йўҳпјҡ
дҪ жҳҜеңЁеҲҶжһҗзӨҫдәӨеӘ’дҪ“её–еӯҗпјҲз”ЁжҲ·иҜ„и®әпјүиҝҳжҳҜж–°й—»пјҹ
дҪ зҡ„еә”з”ЁзЁӢеәҸжҳҜй’ҲеҜ№ејҖж”ҫйўҶеҹҹиҝҳжҳҜзү№е®ҡзҡ„еһӮзӣҙйўҶеҹҹпјҹ
иҜҘи§ЈеҶіж–№жЎҲжһ„е»әеңЁе“Әз§Қж–№жі•дёҠпјҹе®ғдҪҝз”Ёд»Җд№Ҳж ·зҡ„зү№еҫҒпјҹ
е®ғдҪҝз”ЁдәҶд»Җд№Ҳж ·зҡ„и®ӯз»ғж•°жҚ®пјҹ ж•°жҚ®йӣҶи¶іеӨҹеӨ§еҗ—пјҹ ж•°жҚ®йӣҶеҜ№дәҺдҪ зҡ„еә”з”ЁиҖҢиЁҖжңүд»ЈиЎЁжҖ§еҗ—пјҹ
е®ғеЈ°з§°зҡ„еҮҶзЎ®еәҰжҳҜеҰӮдҪ•иЎЎйҮҸзҡ„пјҹ е®ғжҳҜеҹәдәҺдёҖдёӘе°Ҹзҡ„е°Ғй—ӯзҡ„ж•°жҚ®йӣҶпјҢиҝҳжҳҜд»Һи®ӯз»ғж ·жң¬дёӯжҸҗеҸ–зҡ„ж•°жҚ®йӣҶпјҢиҝҳжҳҜеҹәдәҺеӨ§еһӢзҡ„ејҖж”ҫејҸжөӢиҜ•йӣҶпјҹ
и®ӯз»ғе’ҢжөӢиҜ•ж•°жҚ®жҳҜеҗҰз”ұеӨҡдёӘжіЁйҮҠиҖ…ж Үи®°пјҹ з ”з©¶иҖ…们йҮҮеҸ–дәҶе“ӘдәӣжҺӘж–ҪжқҘжңҖеӨ§йҷҗеәҰең°еҮҸе°‘жіЁйҮҠ/иҜ„дј°зҡ„дё»и§ӮжҖ§пјҹ
и§ЈеҶіж–№жЎҲд»…ж”ҜжҢҒж–ҮжЎЈзә§зҡ„жғ…ж„ҹеҲҶжһҗеҗ—пјҹе®ғжҳҜеҗҰж”ҜжҢҒйқўеҗ‘иҜқйўҳжҲ–е®һдҪ“зҡ„еҲҶжһҗпјҹ
жң¬ж–ҮеҺҹж–Үпјҡhttps://www.linkedin.com/pulse/sentiment-analysis-non-technical-technical-guide-dr-chao-he/
жң¬ж–ҮиҜ‘иҖ…пјҡеҗҙз¬ӣпјҢ科еӨ§и®ҜйЈһдә§е“Ғз»ҸзҗҶпјҢйӣҶжҷәдҝұд№җйғЁеҝ—ж„ҝиҖ…пјҢзҺ°д»»жіЁж„ҸеҠӣдёҺзҹҘиҜҶз®ЎзҗҶеҫ®дҝЎзҫӨзҫӨдё»пјҢ笔记дҝЎжҒҜз®ЎзҗҶ专家пјҢзҷҫ科зҹҘиҜҶзҲұеҘҪиҖ…пјҢзҹҘд№ҺзҹҘеҗҚзӯ”дё»пјҲж“…й•ҝиҜқйўҳпјҡ笔记管зҗҶгҖҒеӯҰд№ ж–№жі•зӯүпјүпјҢж“…й•ҝз”Ёз”өи„‘е’ҢжүӢжңәжҗһе®ҡ笔记管зҗҶпјҢжҖқз»ҙеҜјеӣҫпјҢжҰӮеҝөеӣҫпјҢеҗҜеҸ‘дҝЎжҒҜзҪ‘з»ңеӣҫзӯүгҖӮ
йӣҶжҷәQQзҫӨпҪң292641157
е•ҶеҠЎеҗҲдҪңпҪңzhangqian@swarma.org
жҠ•зЁҝиҪ¬иҪҪпҪңwangting@swarma.org
в—Ҷ в—Ҷ в—Ҷ |  еҚҒдәҢжҳҹеә§жңҲд»ҪиЎЁеӨ§жҸӯз§ҳеҝ«жқҘзңӢзңӢдҪ жҳҜ
еҚҒдәҢжҳҹеә§жңҲд»ҪиЎЁеӨ§жҸӯз§ҳеҝ«жқҘзңӢзңӢдҪ жҳҜ
 еҗҚеҲ©еҸҢ收:иҝҷдәӣеЁұд№җз•ҢдәәеЈ«йғҪдёҠиҝҮзҰҸ
еҗҚеҲ©еҸҢ收:иҝҷдәӣеЁұд№җз•ҢдәәеЈ«йғҪдёҠиҝҮзҰҸ
 еЁұд№җеҢ–иҗҘй”Җжңүж–°зҺ©жі•зңҹеҝ«д№җAPPи¶Је‘і
еЁұд№җеҢ–иҗҘй”Җжңүж–°зҺ©жі•зңҹеҝ«д№җAPPи¶Је‘і
 жі•еӣҪеҮәйҒ“гҖҒеӣ жҲҸз”ҹжғ…зҡ„еЁұд№җеңҲгҖҢжЁЎиҢғ
жі•еӣҪеҮәйҒ“гҖҒеӣ жҲҸз”ҹжғ…зҡ„еЁұд№җеңҲгҖҢжЁЎиҢғ
 гҖҗиЎҢдёҡиҒҡз„ҰгҖ‘йӣҶеҗҲиө„йҮ‘дҝЎжүҳзәіе…Ҙе…¶д»–
гҖҗиЎҢдёҡиҒҡз„ҰгҖ‘йӣҶеҗҲиө„йҮ‘дҝЎжүҳзәіе…Ҙе…¶д»–
 иЎҢдёҡиҒҡз„Ұ!еӮЁиғҪж¶ІеҶ·д»·еҖјжҡҙеўһ,жҲ–е°ҶжҲҗ
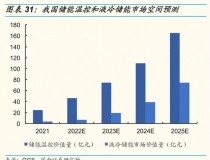
иЎҢдёҡиҒҡз„Ұ!еӮЁиғҪж¶ІеҶ·д»·еҖјжҡҙеўһ,жҲ–е°ҶжҲҗ
 гҖҗиЎҢдёҡиҒҡз„ҰгҖ‘йҮҚеӨ§!ж¶үжҹҗдҝЎжүҳе…¬еҸё!7.
гҖҗиЎҢдёҡиҒҡз„ҰгҖ‘йҮҚеӨ§!ж¶үжҹҗдҝЎжүҳе…¬еҸё!7.
 зңҒзә§дјҳз§ҖжЎҲдҫӢ!е№іжұҹе…ҘйҖү!
зңҒзә§дјҳз§ҖжЎҲдҫӢ!е№іжұҹе…ҘйҖү!