дҪңиҖ… | Kevin Shen
иҜ‘иҖ… | Monanfei
еҮәе“Ғ | AI科жҠҖеӨ§жң¬иҗҘпјҲID: rgznai100пјү
гҖҗеҜјиҜ»гҖ‘жңҖиҝ‘пјҢж·ұеәҰеӯҰд№ еңЁиҮӘ然иҜӯиЁҖеӨ„зҗҶйўҶеҹҹпјҲNLPпјүеҸ–еҫ—дәҶеҫҲеӨ§зҡ„иҝӣжӯҘгҖӮйҡҸзқҖиҜёеҰӮ Attention е’Ң Transformers д№Ӣзұ»ж–°еҸ‘жҳҺзҡ„еҮәзҺ°пјҢBERT е’Ң XLNet дёҖж¬Ўж¬ЎеҸ–еҫ—иҝӣжӯҘпјҢдҪҝеҫ—ж–Үжң¬жғ…ж„ҹиҜҶеҲ«д№Ӣзұ»зҡ„зӯүд»»еҠЎеҸҳеҫ—жӣҙеҠ е®№жҳ“гҖӮжң¬ж–Үе°Ҷд»Ӣз»ҚдёҖз§Қж–°зҡ„ж–№жі•пјҢиҜҘж–№жі•дҪҝз”ЁеӣҫжЁЎеһӢеңЁеҜ№иҜқдёӯиҝӣиЎҢжғ…ж„ҹиҜҶеҲ«гҖӮ
д»Җд№ҲжҳҜжғ…ж„ҹиҜҶеҲ«пјҹ
з®ҖиҖҢиЁҖд№ӢпјҢжғ…ж„ҹиҜҶеҲ«пјҲERCпјүжҳҜеҜ№ж–Үеӯ—иғҢеҗҺзҡ„жғ…ж„ҹиҝӣиЎҢеҲҶзұ»зҡ„д»»еҠЎгҖӮдҫӢеҰӮпјҢз»ҷе®ҡдёҖж®өж–Үеӯ—пјҢдҪ иғҪиҜҙеҮәиҜҙиҜқиҖ…жҳҜз”ҹж°”гҖҒеҝ«д№җгҖҒжӮІдјӨиҝҳжҳҜеӣ°жғ‘еҗ—пјҹжғ…ж„ҹиҜҶеҲ«еңЁеҢ»з–—дҝқеҒҘгҖҒж•ҷиӮІгҖҒй”Җе”®е’ҢдәәеҠӣиө„жәҗж–№йқўе…·жңүи®ёеӨҡе№ҝжіӣзҡ„еә”з”ЁгҖӮд»ҺжңҖй«ҳзҡ„дёҖдёӘеұӮйқўи®ІпјҢжғ…ж„ҹиҜҶеҲ«д»»еҠЎйқһеёёжңүз”ЁпјҢеӣ дёәи®ёеӨҡдәәи®ӨдёәпјҢиҝҷжҳҜжһ„е»әиғҪеӨҹдёҺдәәзұ»еҜ№иҜқзҡ„жҷәиғҪ AI зҡ„еҹәзҹігҖӮ
[img=645,auto]http://5b0988e595225.cdn.sohucs.com/images/20191106/ec959d83b24d48a180dc0fc6d80756f2.png[/img]
ERC её®еҠ©еҒҘеә·еҠ©зҗҶзҡ„дҫӢеӯҗпјҲеӣҫзүҮжқҘжәҗдәҺи®әж–Ү1пјү
еҪ“еүҚпјҢеӨ§еӨҡж•° ERC жүҖеҹәдәҺзҡ„дёӨдёӘдё»иҰҒзҡ„йқ©ж–°жҠҖжңҜжҳҜйҖ’еҪ’зҘһз»ҸзҪ‘з»ңпјҲRNNпјүе’ҢжіЁж„ҸеҠӣжңәеҲ¶гҖӮиҜёеҰӮ LSTM е’Ң GRU д№Ӣзұ»зҡ„ RNN иғҪеӨҹдҫқж¬ЎжҹҘзңӢж–Үжң¬гҖӮеҪ“ж–Үжң¬еҫҲй•ҝж—¶пјҢејҖе§ӢйғЁеҲҶзҡ„жЁЎеһӢи®°еҝҶдјҡдёўеӨұгҖӮиҖҢйҖҡиҝҮз»ҷдёҚеҗҢзҡ„иҜӯеҸҘиҝӣиЎҢеҠ жқғпјҢжіЁж„ҸжңәеҲ¶иғҪеӨҹеҫҲеҘҪең°и§ЈеҶіиҝҷдёҖй—®йўҳгҖӮ
дҪҶжҳҜпјҢRNNs + Attention еңЁиҖғиҷ‘жқҘиҮӘзӣёйӮ»еәҸеҲ—д»ҘеҸҠиҜҙиҜқиҖ…зҡ„дёӘжҖ§гҖҒдё»йўҳе’Ңж„Ҹеӣҫзҡ„дёҠдёӢж–Үж—¶д»Қ然дјҡйҒҮеҲ°еӣ°йҡҫгҖӮеҶҚеҠ дёҠзјәд№Ҹз”ЁдәҺдёӘжҖ§/жғ…з»Әзҡ„ж Үи®°еҹәеҮҶж•°жҚ®йӣҶпјҢдёҚд»…иҰҒе®һж–ҪиҖҢдё”иҝҳиҰҒиЎЎйҮҸж–°жЁЎеһӢзҡ„з»“ж•ҲжһңпјҢиҝҷзЎ®е®һеҸҳеҫ—йқһеёёеӣ°йҡҫгҖӮжңҖиҝ‘зҡ„дёҖзҜҮи®әж–ҮгҖҠDialogueGCN: A Graph Convolutional Neural Network for Emotion Recognition in Conversation гҖӢдҪҝз”ЁдәҶеӣҫеҚ·з§ҜзҘһз»ҸзҪ‘з»ңпјҢйҮҮз”ЁдёҖз§ҚзӣёеҜ№еҲӣж–°зҡ„ж–№жі•и§ЈеҶідәҶи®ёеӨҡй—®йўҳпјҢжң¬ж–Үе°ҶеҜ№иҝҷзҜҮи®әж–ҮиҝӣиЎҢд»Ӣз»Қе’ҢжҖ»з»“гҖӮ
[img=908,auto]http://5b0988e595225.cdn.sohucs.com/images/20191106/1eea20eda9f84eb09ee116cf979de823.png[/img]
дёҠдёӢж–ҮеҫҲйҮҚиҰҒ
еңЁеҜ№иҜқдёӯпјҢдёҠдёӢж–ҮеҫҲйҮҚиҰҒгҖӮз®ҖеҚ•зҡ„ вҖң OkayвҖқ еҸҜд»ҘиЎЁзӨә вҖң OkayпјҹвҖқпјҢвҖң OkayпјҒвҖқ жҲ– вҖң Okay ...вҖқ гҖӮиҝҷеҸ–еҶідәҺдҪ е’ҢеҜ№ж–№д№ӢеүҚиҜҙиҝҮзҡ„еҶ…е®№пјҢдҪ зҡ„ж„ҹеҸ—пјҢеҜ№ж–№зҡ„ж„ҹеҸ—пјҢзҙ§еј зЁӢеәҰд»ҘеҸҠи®ёеӨҡе…¶д»–еӣ зҙ гҖӮйҮҚиҰҒзҡ„дёҠдёӢж–Үдё»иҰҒжңүдёӨз§Қпјҡ
еәҸеҲ—зҡ„дёҠдёӢж–ҮпјҡеәҸеҲ—дёӯеҸҘеӯҗзҡ„еҗ«д№үгҖӮиҜҘдёҠдёӢж–ҮеӨ„зҗҶиҝҮеҺ»зҡ„еҚ•иҜҚеҰӮдҪ•еҪұе“ҚжңӘжқҘзҡ„еҚ•иҜҚгҖҒеҚ•иҜҚзҡ„е…ізі»д»ҘеҸҠиҜӯд№ү/еҸҘжі•зү№еҫҒгҖӮRNN жЁЎеһӢиҖғиҷ‘дәҶеәҸеҲ—зҡ„дёҠдёӢж–ҮгҖӮ
иҜҙиҜқиҖ…зә§еҲ«зҡ„дёҠдёӢж–ҮпјҡиҜҙиҜқиҖ…зӣёдә’д»ҘеҸҠиҮӘиә«зҡ„дҫқиө–жҖ§гҖӮиҝҷз§Қжғ…еҶөж¶үеҸҠиҜҙиҜқиҖ…д№Ӣй—ҙзҡ„е…ізі»д»ҘеҸҠиҮӘжҲ‘дҫқиө–жҖ§пјҡиҮӘе·ұзҡ„дёӘжҖ§дјҡж”№еҸҳ并еҪұе“ҚдҪ еңЁи°ҲиҜқиҝҮзЁӢдёӯзҡ„иҜҙиҜқж–№ејҸгҖӮ
дҪ еҸҜиғҪдјҡзҢңеҲ°пјҢеӨ§еӨҡж•°жЁЎеһӢеҫҲйҡҫиҖғиҷ‘еҲ°иҜҙиҜқиҖ…зә§еҲ«зҡ„дёҠдёӢж–ҮгҖӮдәӢе®һиҜҒжҳҺпјҢжҲ‘们еҸҜд»ҘдҪҝз”ЁеӣҫеҚ·з§ҜзҘһз»ҸзҪ‘з»ңжқҘиҝӣиЎҢиҝҷз§ҚеҪўејҸзҡ„е»әжЁЎпјҢиҖҢиҝҷжӯЈжҳҜ DialogueGCN жүҖйҮҮз”Ёзҡ„ж–№жі•гҖӮ
е°ҶеҜ№иҜқиЎЁзӨәдёәеӣҫеҪў
еңЁдёҖж®өеҜ№иҜқдёӯпјҢMдёӘиҜҙиҜқиҖ…/еҸӮеҠ иҖ…иЎЁзӨәдёә p [1], p [2],...,p [M]гҖӮжҜҸж®өеҸ‘иЁҖпјҲжҹҗдёӘдәәеҸ‘йҖҒзҡ„дёҖж®өж–Үеӯ—пјүиў«иЎЁзӨәдёәU [1],U [2] ,..., u [N]гҖӮERC зҡ„жңҖз»Ҳзӣ®ж ҮжҳҜеҮҶзЎ®ең°е°ҶжҜҸж®өеҸ‘иЁҖйў„жөӢдёәеҝ«д№җгҖҒжӮІдјӨгҖҒдёӯз«ӢгҖҒж„ӨжҖ’гҖҒжҝҖеҠЁгҖҒжІ®дё§гҖҒеҺҢжҒ¶жҲ–жҒҗжғ§дёӯзҡ„дёҖз§ҚгҖӮ
ж•ҙдёӘеҜ№иҜқеҸҜд»Ҙжһ„е»әдёәеҰӮдёӢжүҖзӨәзҡ„жңүеҗ‘еӣҫпјҡ
[img=799,auto]http://5b0988e595225.cdn.sohucs.com/images/20191106/475abc5a1f7e4931afc4e4e5281fd58c.png[/img]
дёҖеј еҢ…еҗ« 2 дёӘиҜҙиҜқиҖ…е’Ң 5 дёӘеҸҘеӯҗзҡ„еҜ№иҜқеӣҫ
G =пјҲVпјҢEпјҢRпјҢWпјү
иҜӯж®өдҪңдёәиҠӮзӮ№пјҲVпјүгҖӮиҫ№пјҲEпјүжҳҜиҠӮзӮ№д№Ӣй—ҙзҡ„и·Ҝеҫ„/иҝһжҺҘгҖӮе…ізі»пјҲRпјүжҳҜиҫ№зҡ„дёҚеҗҢзұ»еһӢ/ж ҮзӯҫгҖӮиҫ№жқғеҖјпјҲWпјүд»ЈиЎЁиҫ№зҡ„йҮҚиҰҒжҖ§гҖӮ
дёӨдёӘиҠӮзӮ№ v е’Ң v[j] д№Ӣй—ҙзҡ„жҜҸдёӘиҫ№йғҪжңүдёӨдёӘеұһжҖ§пјҡе…ізі»пјҲrпјүе’ҢжқғйҮҚпјҲwпјүгҖӮ
иҜҘеӣҫжҳҜжңүеҗ‘зҡ„гҖӮеӣ жӯӨпјҢжүҖжңүиҫ№йғҪжҳҜзӢ¬зү№зҡ„и·Ҝеҫ„гҖӮд»Һv еҲ° v[j] зҡ„иҫ№дёҚеҗҢдәҺд»Һ v[j] еҲ° v зҡ„иҫ№гҖӮ
д»ҺеӣҫдёӯжҲ‘们еҸҜд»ҘзңӢеҲ°пјҢжҜҸдёӘиҜӯж®өйғҪжңүдёҖжқЎдёҺе…¶иҮӘиә«зӣёиҝһзҡ„иҫ№гҖӮиҝҷд»ЈиЎЁдәҶиҜқиҜӯдёҺе…¶иҮӘиә«зҡ„е…ізі»гҖӮжӣҙйҖҡдҝ—ең°и®ІпјҢиҝҷд»ЈиЎЁдәҶеҸ‘еЈ°еҰӮдҪ•еҪұе“ҚеҸ‘иҜқиҖ…зҡ„жҖқжғігҖӮ
дёҠдёӢж–ҮзӘ—еҸЈ
еӣҫиЎЁзӨәзҡ„дёҖдёӘдё»иҰҒй—®йўҳжҳҜпјҢеҰӮжһңеҜ№иҜқеҫҲй•ҝпјҢеҲҷеҚ•дёӘиҠӮзӮ№еҸҜиғҪжңүи®ёеӨҡиҫ№гҖӮиҖҢдё”пјҢз”ұдәҺжҜҸдёӘиҠӮзӮ№йғҪдёҺе…¶д»–иҠӮзӮ№зӣёиҝһпјҢеӣ жӯӨйҡҸзқҖеӣҫзҡ„еӨ§е°ҸеўһеҠ пјҢиҠӮзӮ№зҡ„иҫ№ж•°дјҡе‘Ҳе№іж–№еўһеҠ гҖӮиҝҷе°Ҷж¶ҲиҖ—еӨ§йҮҸзҡ„и®Ўз®—иө„жәҗгҖӮ
дёәдәҶи§ЈеҶіиҜҘй—®йўҳпјҢDialogueGCN еҹәдәҺе…·жңүзү№е®ҡе°әеҜёзҡ„дёҠдёӢж–ҮзӘ—еҸЈжһ„йҖ еӣҫиЎЁзӨәзҡ„иҫ№гҖӮеӣ жӯӨпјҢеҜ№дәҺжҹҗиҠӮзӮ№ iпјҢеңЁеӣҫдёӯд»…иҝһжҺҘеңЁиҝҮеҺ»зӘ—еҸЈе’Ңе°ҶжқҘзӘ—еҸЈиҢғеӣҙеҶ…зҡ„иҠӮзӮ№гҖӮ
[img=868,auto]http://5b0988e595225.cdn.sohucs.com/images/20191106/7fbc90f5c92a4bdcb6a5cbf23dc362aa.png[/img]
еӣҙ绕第дёүеҸҘиҜқеӨ§е°Ҹдёә 1 зҡ„дёҠдёӢж–ҮзӘ—еҸЈ
иҫ№жқғеҖј
дҪҝз”ЁжіЁж„ҸеҠӣжңәеҲ¶и®Ўз®—иҫ№жқғеҖјгҖӮи®ҫзҪ®жіЁж„ҸеҠӣпјҢдҪҝеҫ—жҜҸдёӘиҠӮзӮ№зҡ„е…Ҙиҫ№жқғйҮҚд№Ӣе’Ңдёә1гҖӮиҫ№жқғеҖјжҳҜжҒ’е®ҡзҡ„пјҢеңЁеӯҰд№ иҝҮзЁӢдёӯдёҚдјҡж”№еҸҳгҖӮз®ҖеҚ•жқҘиҜҙпјҢиҫ№жқғеҖјд»ЈиЎЁдәҶдёӨдёӘиҠӮзӮ№д№Ӣй—ҙиҝһжҺҘзҡ„йҮҚиҰҒжҖ§гҖӮ
е…ізі»
иҫ№зҡ„е…ізі»еҸ–еҶідәҺдёӨ件дәӢпјҡ
иҜҙиҜқиҖ…дҫқиө–жҖ§пјҡи°ҒиҜҙиҝҮ uпјҹи°ҒиҜҙ v[j]пјҹ
ж—¶й—ҙдҫқиө–жҖ§пјҡu жҳҜеңЁ u[j] д№ӢеүҚеҸ‘еҮәзҡ„пјҢиҝҳжҳҜд№ӢеҗҺпјҹ
еңЁеҜ№иҜқдёӯпјҢеҰӮжһңжңү M дёӘдёҚеҗҢзҡ„и®ІиҜқиҖ…пјҢеҲҷжңҖеӨҡдјҡжңү M пјҲu[j] зҡ„и®ІиҜқиҖ…пјү* MпјҲu[j] зҡ„и®ІиҜқиҖ…пјү* 2пјҲu жҳҜеҗҰеңЁ u [j] д№ӢеүҚеҮәзҺ°пјҢжҲ–д№ӢеҗҺпјү= 2M ВІ дёӘе…ізі»гҖӮ
жҲ‘们еҸҜд»Ҙд»ҺдёҠйқўзҡ„зӨәдҫӢеӣҫдёӯеҲ—еҮәжүҖжңүзҡ„е…ізі»пјҢеҰӮдёӢеӣҫжүҖзӨәпјҡ
[img=637,auto]http://5b0988e595225.cdn.sohucs.com/images/20191106/aa60bfd8d1ef4f5daca9949122e44987.png[/img]
дҫӢеӯҗдёӯжүҖжңүеҸҜиғҪзҡ„е…ізі»еҲ—иЎЁ
дёӢеӣҫжүҖзӨәдёәеҗҢдёҖдёӘеӣҫпјҢе…¶дёӯиҫ№зҡ„е…ізі»ж №жҚ®иЎЁж јиҝӣиЎҢдәҶж Үи®°пјҡ
[img=741,auto]http://5b0988e595225.cdn.sohucs.com/images/20191106/c134a7f8edf74876a35816cac2de9fc0.png[/img]
иҫ№зјҳж Үи®°жңүеҗ„иҮӘзҡ„е…ізі»пјҲиҜ·еҸӮи§ҒдёҠиЎЁпјү
еңЁжҲ‘们зҡ„дҫӢеӯҗдёӯпјҢжҲ‘们жңү 8 дёӘдёҚеҗҢзҡ„е…ізі»гҖӮеңЁиҫғй«ҳзҡ„еұӮж¬ЎдёҠпјҢе…ізі»жҳҜиҫ№зҡ„йҮҚиҰҒеұһжҖ§пјҢеӣ дёәеңЁеҜ№иҜқдёӯи°ҒиҜҙд»Җд№Ҳе’Ңд»Җд№Ҳж—¶еҖҷиҜҙйғҪеҫҲйҮҚиҰҒгҖӮеҰӮжһң Peter й—®дёҖдёӘй—®йўҳиҖҢ Jenny еӣһзӯ”пјҢеҲҷдёҚеҗҢдәҺ Jenny е…ҲиҜҙзӯ”жЎҲпјҢ然еҗҺ Peter й—®иҝҷдёӘй—®йўҳпјҲж—¶й—ҙдҫқиө–жҖ§пјүгҖӮеҗҢж ·пјҢеҰӮжһң Peter еҗ‘ Jenny е’Ң Bob жҸҗеҮәзӣёеҗҢзҡ„й—®йўҳпјҢ他们зҡ„еӣһзӯ”еҸҜиғҪдјҡжңүжүҖдёҚеҗҢпјҲиҜҙиҜқиҖ…дҫқиө–жҖ§пјүгҖӮ
е°Ҷе…ізі»и§Ҷдёәе®ҡд№үиҝһжҺҘзҡ„зұ»еһӢпјҢиҖҢиҫ№жқғеҖјд»ЈиЎЁиҝһжҺҘзҡ„йҮҚиҰҒжҖ§гҖӮ
жЁЎеһӢ
DialogueGCN жЁЎеһӢдҪҝз”ЁдёҖз§Қз§°дёәеӣҫеҚ·з§ҜзҪ‘з»ңпјҲGCNпјүзҡ„еӣҫзҘһз»ҸзҪ‘з»ңгҖӮ
е°ұеғҸдёҠйқўдёҖж ·пјҢдёӢеӣҫжүҖзӨәдёә 2 дёӘиҜҙиҜқиҖ…зҡ„ 5 ж®өеҜ№иҜқзҡ„еӣҫгҖӮ
[img=1238,auto]http://5b0988e595225.cdn.sohucs.com/images/20191106/9ce5a846acfc4b43a4ebe99474aa461d.jpeg[/img]
еӣҫзүҮжқҘжәҗдәҺи®әж–Ү 1
еңЁйҳ¶ж®ө 1 дёӯпјҢжҜҸдёӘиҜӯж®ө u иЎЁзӨәдёәдёҖдёӘзү№еҫҒеҗ‘йҮҸпјҢиҜҘеҗ‘йҮҸеҗ«жңүеҜ№иҜқзҡ„йЎәеәҸдҝЎжҒҜгҖӮиҜҘиҝҮзЁӢз”ұдёҖдёӘйЎәеәҸдёҠдёӢж–Үзј–з ҒеҷЁзҡ„ GRU е®һзҺ°пјҡе°ҶжҜҸдёӘиҜӯж®өжҢүз…§йЎәеәҸиҫ“е…ҘиҜҘдёҠдёӢж–Үзј–з ҒеҷЁгҖӮйҳ¶ж®ө 1 дёҚйңҖиҰҒеӣҫз»“жһ„гҖӮе…·жңүйЎәеәҸдёҠдёӢж–Үзҡ„ж–°иҜӯж®өиЎЁзӨәдёә g[1] ,..., g[N]гҖӮиҝҷжҳҜ GCN зҡ„иҫ“е…ҘгҖӮ
[img=1239,auto]http://5b0988e595225.cdn.sohucs.com/images/20191106/436f4365c3854966b3bb7db50e282f9f.jpeg[/img]
еңЁйҳ¶ж®ө 2 дёӯпјҢиҜҘжЁЎеһӢе°Ҷжһ„е»әдёҖдёӘеҰӮеүҚж–ҮжүҖиҝ°зҡ„еӣҫпјҢ并дҪҝз”Ёзү№еҫҒиҪ¬жҚўе°ҶиҜҙиҜқиҖ…зә§еҲ«зҡ„дёҠдёӢж–Үж·»еҠ еҲ°еӣҫдёӯгҖӮh[1] ,..., h[N] иЎЁзӨәеәҸеҲ—зә§еҲ«е’ҢиҜҙиҜқиҖ…зә§еҲ«зҡ„дёҠдёӢж–ҮгҖӮиҝҷжҳҜ GCN зҡ„иҫ“еҮәгҖӮ
иҫ№е’ҢиҠӮзӮ№зҡ„еӨ–и§Ӯе·®ејӮпјҲиҷҡvsе®һгҖҒдёҚеҗҢзҡ„йўңиүІпјүиЎЁзӨәдёҚеҗҢзҡ„е…ізі»гҖӮдҫӢеҰӮпјҢз»ҝиүІ g[1] еҲ°з»ҝиүІ g[3] зҡ„иҫ№дёәз»ҝиүІе®һзәҝд»ЈиЎЁе…ізі»1гҖӮ
зү№еҫҒиҪ¬жҚўвҖ”вҖ”еөҢе…ҘиҜҙиҜқиҖ…зә§еҲ«зҡ„дёҠдёӢж–Ү
GCN жңҖйҮҚиҰҒзҡ„жӯҘйӘӨд№ӢдёҖжҳҜзү№еҫҒиҪ¬жҚўвҖ”вҖ”еҰӮдҪ•е°ҶиҜҙиҜқиҖ…зә§еҲ«зҡ„дёҠдёӢж–ҮеөҢе…ҘеҲ°иҜқиҜӯдёӯгҖӮжҲ‘们е°ҶйҰ–е…Ҳи®Ёи®әжүҖдҪҝз”Ёзҡ„жҠҖжңҜпјҢ然еҗҺжҸҸиҝ°е…¶иғҢеҗҺзҡ„зӣҙи§үгҖӮ
зү№еҫҒиҪ¬жҚўжңүдёӨдёӘжӯҘйӘӨгҖӮ
еңЁз¬¬ 1 жӯҘдёӯпјҢеҜ№дәҺжҜҸдёӘиҠӮзӮ№hпјҢзӣёйӮ»иҠӮзӮ№зҡ„дҝЎжҒҜпјҲдёҠдёӢж–ҮзӘ—еҸЈеҶ…зҡ„иҠӮзӮ№пјүиў«иҒҡйӣҶпјҢз”Ёд»ҘеҲӣе»әж–°зҡ„зү№еҫҒеҗ‘йҮҸhВ№ гҖӮ
[img=1148,auto]http://5b0988e595225.cdn.sohucs.com/images/20191106/14dcf032d3814a9895cbd664ead9f756.jpeg[/img]
иҜҘеҮҪж•°зңӢиө·жқҘеҫҲеӨҚжқӮпјҢдҪҶе…¶ж ёеҝғеҸӘжҳҜзҪ‘з»ңдёӯе…·жңүеҸҜеӯҰд№ еҸӮж•° W[o]В№ е’Ң W[r]В№ зҡ„еұӮгҖӮжӯӨеӨ–пјҢиҝҳйңҖиҰҒж·»еҠ еҪ’дёҖеҢ–еёёж•° c[i,r]гҖӮиҝҷдәӣеҸӮж•°еҸҜд»Ҙйў„е…Ҳи®ҫзҪ®пјҢд№ҹеҸҜд»ҘйҖҡиҝҮзҪ‘з»ңжң¬иә«жқҘеӯҰд№ гҖӮ
еҰӮеүҚжүҖиҝ°пјҢиҫ№жқғеҖјжҳҜжҒ’е®ҡзҡ„пјҢеңЁиҝҮзЁӢдёӯдёҚдјҡжӣҙж”№жҲ–еӯҰд№ гҖӮ
еңЁз¬¬ 2 жӯҘдёӯпјҢеҶҚж¬Ўжү§иЎҢзӣёеҗҢзҡ„ж“ҚдҪңгҖӮйӮ»еұ…дҝЎжҒҜиў«жұҮжҖ»пјҢ并且зұ»дјјзҡ„еҮҪж•°иў«еә”з”ЁдәҺжҺҘ收жӯҘйӘӨ 1 зҡ„иҫ“еҮәгҖӮеңЁиҝҷйҮҢпјҢжҲ‘们дҪҝз”Ё WВІ е’ҢW[o]ВІ д»ЈиЎЁи®ӯз»ғиҝҮзЁӢдёӯеҸҜеӯҰд№ зҡ„еҸӮж•°гҖӮ
[img=1108,auto]http://5b0988e595225.cdn.sohucs.com/images/20191106/3309663bcf974ceab77f79c23c07c511.jpeg[/img]
е…¬ејҸ2пјҲ第дәҢжӯҘпјү
еңЁиҫғй«ҳзә§еҲ«дёҠпјҢиҝҷдёӨжӯҘзҡ„е®һиҙЁдёҠжҳҜеҜ№жҜҸдёӘиҜӯж®өзҡ„зӣёйӮ»иҜӯж®өдҝЎжҒҜиҝӣиЎҢеҪ’дёҖеҢ–жұӮе’ҢгҖӮд»Һжӣҙж·ұеұӮж¬ЎдёҠи®ІпјҢиҝҷдёӨжӯҘиҪ¬еҢ–зҡ„еҹәзЎҖжҳҜз®ҖеҚ•зҡ„еҸҜеҢәеҲҶж¶ҲжҒҜдј йҖ’жЎҶжһ¶ [2]пјҲhttps://arxiv.org/pdf/1704.01212.pdfпјүгҖӮз ”з©¶дәәе‘ҳйҮҮз”Ёиҝҷз§ҚжҠҖжңҜжқҘз ”з©¶еӣҫеҚ·з§ҜзҘһз»ҸзҪ‘з»ңпјҢд»ҺиҖҢеҜ№е…ізі»ж•°жҚ®иҝӣиЎҢе»әжЁЎ [3]пјҲhttps://arxiv.org/abs/1703.06103пјүгҖӮеҰӮжһңдҪ жңүз©әй—Ізҡ„ж—¶й—ҙпјҢжҲ‘们ејәзғҲе»әи®®дҪ жҢүйЎәеәҸйҳ…иҜ»иҝҷдёӨзҜҮи®әж–ҮгҖӮDialogueGCN зҡ„зү№еҫҒиҪ¬жҚўиҝҮзЁӢиғҢеҗҺзҡ„зӣҙи§үйғҪеңЁиҝҷдёӨзҜҮи®әж–ҮдёӯгҖӮ
GCNзҡ„иҫ“еҮәеңЁеӣҫдёӯз”Ё h [1] ,..., h [N]иЎЁзӨәгҖӮ
еңЁйҳ¶ж®ө 3 дёӯпјҢе°ҶеҺҹе§Ӣзҡ„йЎәеәҸдёҠдёӢж–Үзј–з Ғеҗ‘йҮҸдёҺиҜҙиҜқиҖ…зә§еҲ«зҡ„дёҠдёӢж–Үзј–з Ғеҗ‘йҮҸиҝӣиЎҢдёІиҒ”гҖӮиҝҷзұ»дјјдәҺе°ҶеҺҹе§ӢеӣҫеұӮдёҺеҗҺйқўзҡ„еӣҫеұӮз»„еҗҲпјҢд»ҺиҖҢвҖңжұҮжҖ»вҖқжҜҸдёӘеӣҫеұӮзҡ„иҫ“еҮәгҖӮ
жҺҘзқҖпјҢжҲ‘们е°Ҷзә§иҒ”зҡ„зү№еҫҒеҗ‘йҮҸйҰҲйҖҒеҲ°е…ЁиҝһжҺҘзҡ„зҪ‘з»ңдёӯиҝӣиЎҢеҲҶзұ»гҖӮжңҖз»Ҳзҡ„иҫ“еҮәжҳҜиҜӯж®өзҡ„дёҚеҗҢжғ…з»Әзҡ„жҰӮзҺҮеҲҶеёғгҖӮ
[img=1296,auto]http://5b0988e595225.cdn.sohucs.com/images/20191106/85ab676db5d04cec9bd058c96c23de8e.jpeg[/img]
и®әж–ҮдҪҝз”ЁеёҰжңү L2 жӯЈеҲҷеҢ–зҡ„еҲҶзұ»дәӨеҸүзҶөжҚҹеӨұпјҲhttps://gombru.github.io/2018/05/23/cross_entropy_loss/пјүжқҘеҜ№жЁЎеһӢиҝӣиЎҢи®ӯз»ғгҖӮдҪҝз”ЁиҜҘжҚҹеӨұеҮҪж•°зҡ„еҺҹеӣ жҳҜпјҢжЁЎеһӢйңҖиҰҒйў„жөӢеӨҡдёӘж ҮзӯҫпјҲжғ…ж„ҹзұ»еҲ«пјүзҡ„жҰӮзҺҮгҖӮ
з»“жһң
еҹәеҮҶж•°жҚ®йӣҶ
еңЁеүҚж–ҮдёӯжҲ‘们жҸҗеҲ°зјәд№ҸеҹәеҮҶж•°жҚ®йӣҶгҖӮйҖҡиҝҮдҪҝз”Ёж Үи®°зҡ„еӨҡжЁЎж•°жҚ®йӣҶпјҲж–Үжң¬гҖҒи§Ҷйў‘жҲ–йҹійў‘пјүпјҢ然еҗҺжҸҗеҸ–е…¶дёӯзҡ„ж–Үжң¬йғЁеҲҶпјҢ并且еҝҪз•Ҙе…¶д»–зҡ„йҹійў‘жҲ–и§Ҷйў‘ж•°жҚ®пјҢи®әж–Үзҡ„дҪңиҖ…е·§еҰҷең°и§ЈеҶідәҶиҜҘй—®йўҳгҖӮ
DialogueGCN еңЁд»ҘдёӢж•°жҚ®йӣҶдёҠиҝӣиЎҢдәҶиҜ„дј°пјҡ
IEMOCAPпјҡи§Ҷйў‘еҪўејҸзҡ„еҚҒдҪҚзӢ¬з«ӢеҸ‘иЁҖдәәзҡ„еҸҢеҗ‘еҜ№иҜқгҖӮиҜӯж®өдёӯеёҰжңүеҝ«д№җгҖҒжӮІдјӨгҖҒдёӯз«ӢгҖҒж„ӨжҖ’гҖҒжҝҖеҠЁжҲ–жІ®дё§зҡ„ж ҮзӯҫгҖӮ
AVECпјҡдәәзұ»дёҺдәәе·ҘжҷәиғҪд№Ӣй—ҙзҡ„еҜ№иҜқгҖӮиҜӯж®өе…·жңүеӣӣдёӘж Үзӯҫпјҡд»·еҖјпјҲ[-1,1]пјүгҖҒе”ӨйҶ’пјҲ[-1пјҢ1]пјүгҖҒжңҹжңӣпјҲ[-1,1]пјүе’ҢиғҪеҠӣпјҲ[0пјҢвҲһ]пјүгҖӮ
MELDпјҡеҢ…еҗ«з”өи§Ҷиҝһз»ӯеү§гҖҠиҖҒеҸӢи®°гҖӢдёӯзҡ„ 1400 дёӘеҜ№иҜқе’Ң 13000 дёӘиҜӯж®өгҖӮMELD иҝҳеҢ…еҗ«дә’иЎҘзҡ„еЈ°йҹіе’Ңи§Ҷи§үдҝЎжҒҜгҖӮиҜӯж®өиў«ж Үи®°дёәж„ӨжҖ’гҖҒеҺҢжҒ¶гҖҒжӮІдјӨгҖҒе–ңжӮҰгҖҒжғҠеҘҮгҖҒжҒҗжғ§жҲ–дёӯз«ӢгҖӮ
MELD е…·жңүйў„е®ҡд№үзҡ„и®ӯз»ғйӣҶгҖҒйӘҢиҜҒйӣҶгҖҒжөӢиҜ•йӣҶгҖӮAVEC е’Ң IEMOCAP жІЎжңүйў„е®ҡд№үзҡ„еҲ’еҲҶпјҢеӣ жӯӨе°Ҷе®ғ们зҡ„ 10пј… еҜ№иҜқз”ЁдҪңйӘҢиҜҒйӣҶгҖӮ
DialogueGCN дёҺи®ёеӨҡеҹәеҮҶжЁЎеһӢе’ҢжңҖж–°жЁЎеһӢиҝӣиЎҢдәҶеҜ№жҜ”гҖӮе…¶дёӯпјҢDialogueRNN жҳҜиҜҘи®әж–ҮжҹҗдҪңиҖ…зҡ„жңҖе…Ҳиҝӣзҡ„жЁЎеһӢгҖӮ
[img=1225,auto]http://5b0988e595225.cdn.sohucs.com/images/20191106/230ae6e994d8464783712aa795cddb60.png[/img]
DialogueGCNдёҺе…¶д»–жЁЎеһӢеңЁIEMOCAPж•°жҚ®йӣҶдёҠзҡ„иЎЁзҺ°пјҲиЎЁж‘ҳиҮӘ[1]пјү
еңЁ IEMOCAP зҡ„ 6 дёӘзұ»еҲ«дёӯзҡ„ 4 дёӘзұ»еҲ«дёӯпјҢзӣёеҜ№дәҺеҢ…жӢ¬ DialogueRNN еңЁеҶ…зҡ„жүҖжңүжЁЎеһӢпјҢDialogueGCN еқҮжҳҫзӨәеҮәжҳҺжҳҫзҡ„ж”№иҝӣгҖӮеңЁвҖңж„ӨжҖ’вҖқзұ»еҲ«дёӯпјҢDialogueGCN жң¬иҙЁдёҠдёҺ DialogueRNN еӯҳеңЁиҒ”зі»пјҲGCN еңЁ F1 иҜ„еҲҶдёҠд»…е·® 1.09пјүпјҢеҸӘжңүвҖңе…ҙеҘӢвҖқзұ»еҲ«жҳҫзӨәеҮәи¶іеӨҹеӨ§зҡ„е·®ејӮгҖӮ
DialogueGCN еңЁ AVEC е’Ң MELD дёҠдә§з”ҹдәҶзӣёдјјзҡ„з»“жһңпјҢи¶…иҝҮдәҶзҺ°жңүзҡ„ DialogueRNNгҖӮ
[img=879,auto]http://5b0988e595225.cdn.sohucs.com/images/20191106/f7da7d1610a740529669f90c92222224.png[/img]
DialogueGCNдёҺе…¶д»–жЁЎеһӢеңЁAVECе’ҢMELDж•°жҚ®йӣҶдёҠзҡ„иЎЁзҺ°пјҲиЎЁж‘ҳиҮӘ[1]пјү
д»Һз»“жһңдёӯеҸҜд»ҘжҳҺжҳҫзңӢеҮәпјҢе°ҶиҜҙиҜқиҖ…зә§еҲ«зҡ„дёҠдёӢж–Үж·»еҠ еҲ°еҜ№иҜқеӣҫдёӯпјҢиҝҷз§Қж–№ејҸеҸҜд»Ҙд»Һжң¬иҙЁдёҠжҸҗй«ҳжЁЎеһӢзҡ„зҗҶи§ЈиғҪеҠӣгҖӮз”ұжӯӨеҸҜи§ҒпјҢDialogueRNN иғҪеӨҹеҫҲеҘҪең°жҚ•иҺ·йЎәеәҸдёҠдёӢж–ҮпјҢдҪҶжҳҜзјәд№ҸеҜ№иҜҙиҜқдәәдёҠдёӢж–ҮиҝӣиЎҢзј–з Ғзҡ„иғҪеҠӣгҖӮ
еҲҶжһҗ
иҜҘе®һйӘҢзҡ„дёҖдёӘеҸӮж•°жҳҜдёҠдёӢж–ҮзӘ—еҸЈзҡ„е°әеҜёгҖӮйҖҡиҝҮжү©еұ•е…¶е°әеҜёпјҢжҲ‘们еҸҜд»Ҙе°Ҷиҫ№зҡ„ж•°йҮҸеўһеҠ еҲ°зү№е®ҡзҡ„иҜӯж®өдёҠгҖӮз ”з©¶е·Із»ҸеҸ‘зҺ°пјҢе°әеҜёзҡ„еўһеҠ иҷҪ然еңЁи®Ўз®—дёҠжӣҙеҠ жҳӮиҙөпјҢдҪҶжҳҜеҸҜд»Ҙж”№е–„з»“жһңгҖӮ
дҪңиҖ…иҝҳиҝӣиЎҢдәҶдёҖдёӘжңүи¶Јзҡ„е®һйӘҢпјҡж¶ҲиһҚз ”з©¶гҖӮдёҖж¬ЎеҸ–дёӢдёҖдёӘзј–з ҒеҷЁпјҢ然еҗҺйҮҚж–°жөӢйҮҸжЁЎеһӢзҡ„жҖ§иғҪгҖӮеҸ‘зҺ°иҜҙиҜқиҖ…зә§дёҠдёӢж–Үзј–з ҒеҷЁпјҲйҳ¶ж®ө2пјүжҜ”йЎәеәҸдёҠдёӢж–Үзј–з ҒеҷЁпјҲйҳ¶ж®ө1пјүжӣҙйҮҚиҰҒгҖӮ
з ”з©¶иҝҳеҸ‘зҺ°пјҢиҜҜеҲҶзұ»еҖҫеҗ‘дәҺеңЁд»ҘдёӢдёӨз§Қжғ…еҶөдёӢеҸ‘з”ҹпјҡ
зұ»дјјзҡ„жғ…з»Әзұ»еҲ«пјҢдҫӢеҰӮвҖңжІ®дё§вҖқе’ҢвҖңз”ҹж°”вҖқпјҢжҲ–вҖңжҝҖеҠЁвҖқе’ҢвҖңеҝ«д№җвҖқгҖӮ
з®Җзҹӯзҡ„иҜқиҜӯпјҢдҫӢеҰӮвҖңеҘҪвҖқжҲ–вҖңжҳҜвҖқгҖӮ
з”ұдәҺжүҖдҪҝз”Ёзҡ„ж•°жҚ®йӣҶйғҪжҳҜеӨҡжЁЎејҸзҡ„пјҢиҖҢдё”еҢ…еҗ«йҹійў‘е’Ңи§Ҷйў‘пјҢеӣ жӯӨеҸҜд»ҘйҖҡиҝҮж•ҙеҗҲйҹійў‘е’Ңи§Ҷи§үеӨҡжЁЎејҸеӯҰд№ жқҘжҸҗй«ҳиҝҷдёӨз§Қжғ…еҶөдёӢзҡ„еҮҶзЎ®жҖ§гҖӮе°Ҫз®Ўд»Қ然еӯҳеңЁеҲҶзұ»й”ҷиҜҜзҡ„й—®йўҳпјҢдҪҶжҳҜ DialogueGCN д»ҚеңЁеҮҶзЎ®жҖ§ж–№йқўеҸ–еҫ—дәҶйқһеёёжҳҫи‘—зҡ„иҝӣжӯҘгҖӮ
йҮҚзӮ№
дёҠдёӢж–ҮеҫҲйҮҚиҰҒгҖӮдёҖдёӘеҘҪзҡ„жЁЎеһӢдёҚд»…иҰҒиҖғиҷ‘еҜ№иҜқзҡ„йЎәеәҸдёҠдёӢж–ҮпјҲеҸҘеӯҗзҡ„йЎәеәҸпјҢеҚ•иҜҚеҪјжӯӨд№Ӣй—ҙзҡ„е…іиҒ”пјүпјҢиҝҳиҰҒиҖғиҷ‘иҜҙиҜқиҖ…зә§еҲ«зҡ„дёҠдёӢж–ҮпјҲиҜҙиҜқиҖ…иҜҙд»Җд№ҲпјҢеҪ“他们иҜҙиҜқж—¶пјҢе®ғ们еҰӮдҪ•еҸ—еҲ°е…¶д»–иҜҙиҜқиҖ…е’ҢиҮӘе·ұзҡ„еҪұе“ҚпјүгҖӮдёҺдј з»ҹзҡ„еәҸеҲ—жЁЎеһӢе’ҢеҹәдәҺжіЁж„ҸеҠӣзҡ„жЁЎеһӢзӣёжҜ”пјҢйӣҶжҲҗиҜҙиҜқиҖ…зә§еҲ«зҡ„дёҠдёӢж–ҮжҳҜдёҖеӨ§иҝӣжӯҘгҖӮ
еәҸеҲ—并дёҚжҳҜд»ЈиЎЁеҜ№иҜқзҡ„е”ҜдёҖж–№ејҸгҖӮж•°жҚ®зҡ„з»“жһ„еҸҜд»Ҙеё®еҠ©жҚ•иҺ·жӣҙеӨҡзҡ„дёҠдёӢж–ҮгҖӮеңЁиҝҷз§Қжғ…еҶөдёӢпјҢиҜҙиҜқиҖ…зә§еҲ«зҡ„дёҠдёӢж–Үжӣҙе®№жҳ“д»ҘеӣҫеҪўж јејҸзј–з ҒгҖӮ
еӣҫзҘһз»ҸзҪ‘з»ңжҳҜ NLP з ”з©¶зҡ„е®қеә“гҖӮиҒҡеҗҲйӮ»еұ…дҝЎжҒҜзҡ„е…ій”®жҰӮеҝөиҷҪ然зңӢдёҠеҺ»з®ҖеҚ•пјҢдҪҶеңЁжҚ•иҺ·ж•°жҚ®дёӯзҡ„е…ізі»ж–№йқўе…·жңүжғҠдәәзҡ„еҠҹиғҪгҖӮ
еҺҹж–Үй“ҫжҺҘпјҡ
https://towardsdatascience.com/emotion-recognition-using-graph-convolutional-networks-9f22f04b244e
пјҲ*жң¬ж–ҮдёәAI科жҠҖеӨ§жң¬иҗҘзј–иҜ‘ж–Үз« пјҢиҪ¬иҪҪиҜ·еҫ®дҝЎиҒ”зі» 1092722531пјү
в—Ҷ
в—Ҷ |  еҗҚеҲ©еҸҢ收:иҝҷдәӣеЁұд№җз•ҢдәәеЈ«йғҪдёҠиҝҮзҰҸ
еҗҚеҲ©еҸҢ收:иҝҷдәӣеЁұд№җз•ҢдәәеЈ«йғҪдёҠиҝҮзҰҸ
 еЁұд№җеҢ–иҗҘй”Җжңүж–°зҺ©жі•зңҹеҝ«д№җAPPи¶Је‘і
еЁұд№җеҢ–иҗҘй”Җжңүж–°зҺ©жі•зңҹеҝ«д№җAPPи¶Је‘і
 жі•еӣҪеҮәйҒ“гҖҒеӣ жҲҸз”ҹжғ…зҡ„еЁұд№җеңҲгҖҢжЁЎиҢғ
жі•еӣҪеҮәйҒ“гҖҒеӣ жҲҸз”ҹжғ…зҡ„еЁұд№җеңҲгҖҢжЁЎиҢғ
 гҖҗиЎҢдёҡиҒҡз„ҰгҖ‘йӣҶеҗҲиө„йҮ‘дҝЎжүҳзәіе…Ҙе…¶д»–
гҖҗиЎҢдёҡиҒҡз„ҰгҖ‘йӣҶеҗҲиө„йҮ‘дҝЎжүҳзәіе…Ҙе…¶д»–
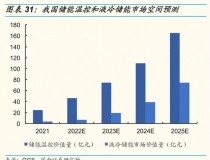 иЎҢдёҡиҒҡз„Ұ!еӮЁиғҪж¶ІеҶ·д»·еҖјжҡҙеўһ,жҲ–е°ҶжҲҗ
иЎҢдёҡиҒҡз„Ұ!еӮЁиғҪж¶ІеҶ·д»·еҖјжҡҙеўһ,жҲ–е°ҶжҲҗ
 гҖҗиЎҢдёҡиҒҡз„ҰгҖ‘йҮҚеӨ§!ж¶үжҹҗдҝЎжүҳе…¬еҸё!7.
гҖҗиЎҢдёҡиҒҡз„ҰгҖ‘йҮҚеӨ§!ж¶үжҹҗдҝЎжүҳе…¬еҸё!7.
 зңҒзә§дјҳз§ҖжЎҲдҫӢ!е№іжұҹе…ҘйҖү!
зңҒзә§дјҳз§ҖжЎҲдҫӢ!е№іжұҹе…ҘйҖү!
 ж—…жёёдёҡзҡ„вҖңе№ҙз»ҲжҠҘе‘ҠвҖқ:еӣҪеҶ…жёёеҚ жҚ®
ж—…жёёдёҡзҡ„вҖңе№ҙз»ҲжҠҘе‘ҠвҖқ:еӣҪеҶ…жёёеҚ жҚ®